Java学习笔记-基础篇
Java程序怎么样运行的
Java 程序从源代码到运行一般有下面 3 步:
我们需要格外注意的是 .class->机器码 这一步。在这一步 JVM 类加载器首先加载字节码文件,然后通过解释器逐行解释执行,这种方式的执行速度会相对比较慢。而且,有些方法和代码块是经常需要被调用的(也就是所谓的热点代码),所以后面引进了 JIT 编译器,而 JIT 属于运行时编译。当 JIT 编译器完成第一次编译后,其会将字节码对应的机器码保存下来,下次可以直接使用。而我们知道,机器码的运行效率肯定是高于 Java 解释器的。这也解释了我们为什么经常会说 Java 是编译与解释共存的语言。
HotSpot 采用了惰性评估(Lazy Evaluation)的做法,根据二八定律,消耗大部分系统资源的只有那一小部分的代码(热点代码),而这也就是 JIT 所需要编译的部分。JVM 会根据代码每次被执行的情况收集信息并相应地做出一些优化,因此执行的次数越多,它的速度就越快。JDK 9 引入了一种新的编译模式 AOT(Ahead of Time Compilation),它是直接将字节码编译成机器码,这样就避免了 JIT 预热等各方面的开销。JDK 支持分层编译和 AOT 协作使用。但是 ,AOT 编译器的编译质量是肯定比不上 JIT 编译器的。
总结:
Java 虚拟机(JVM)是运行 Java 字节码的虚拟机。JVM 有针对不同系统的特定实现(Windows,Linux,macOS),目的是使用相同的字节码,它们都会给出相同的结果。字节码和不同系统的 JVM 实现是 Java 语言“一次编译,随处可以运行”的关键所在。
为什么说 Java 语言“编译与解释并存”?
高级编程语言按照程序的执行方式分为编译型和解释型两种。简单来说,编译型语言是指编译器针对特定的操作系统将源代码一次性翻译成可被该平台执行的机器码;解释型语言是指解释器对源程序逐行解释成特定平台的机器码并立即执行。比如,你想阅读一本英文名著,你可以找一个英文翻译人员帮助你阅读, 有两种选择方式,你可以先等翻译人员将全本的英文名著(也就是源码)都翻译成汉语,再去阅读,也可以让翻译人员翻译一段,你在旁边阅读一段,慢慢把书读完。
Java 语言既具有编译型语言的特征,也具有解释型语言的特征,因为 Java 程序要经过先编译,后解释两个步骤,由 Java 编写的程序需要先经过编译步骤,生成字节码(*.class 文件),这种字节码必须由 Java 解释器来解释执行。因此,我们可以认为 Java 语言编译与解释并存
java与C语言在字符串结束符上的区别
在C语言中字符串或字符数组最后都会有一个额外的字符‘\0’来表示结束,而在java语言中没有结束符这一概念。
参考:https://blog.csdn.net/sszgg2006/article/details/49148189
java中无需结束符的原因
Java里面一切都是对象,是对象的话,字符串肯定就有长度,即然有长度,编译器就可以确定要输出的字符个数,当然也就没有必要去浪费那1字节的空间用以标明字符串的结束了。比如,数组对象里有一个属性length,就是数组的长度,String类里面有方法length()可以确定字符串的长度,因此对于输出函数来说,有直接的大小可以判断字符串的边界,编译器就没必要再去浪费一个空间标识字符串的结束。
java字符串末尾空字符的处理
java和c通信的时候,由于c中的char中有结束符的,所以当java收到C发来的字符串时,后面往往会有若干空字符,如果不做处理的话,java会对其一并输出,为了将空字符处理掉不输出,可以采用如下两种方法:
方法一:
调用java字符串的trim()方法,该方法会将字符串前后的空字符读去掉。
方法二:自己实现去掉尾部空字符的方法
字符型常量和字符串常量的区别?
形式上: 字符常量是单引号引起的一个字符; 字符串常量是双引号引起的若干个字符
含义上: 字符常量相当于一个整型值( ASCII 值),可以参加表达式运算; 字符串常量代表一个地址值(该字符串在内存中存放位置)
占内存大小 字符常量只占 2 个字节; 字符串常量占若干个字节 (注意: char 在 Java 中占两个字节)
java 编程思想第四版:2.2.2 节
JVM内部使用的是UTF-16编码。不管代码文件中char使用的是什么编码,都将被JVM转化为UTF-16而且只用两个字节,也就是说Java中的char占用两个字节,只能表示Unicode中第一层(BMP)中的字符,对于其他字符会报错:Invalid Character Constant, 而String中是可以的。
如果一个抽象的字符在 UTF-16 编码下占 4 字节,显然它是不能放到 char 中的。换言之, char 中只能放 UTF-16 编码下只占 2 字节的那些字符。
String.getBytes()是一个用于将String的内码转换为指定的外码的方法。无参数版使用平台的默认编码作为外码,有参数版使用参数指定的编码作为外码;将String的内容用外码编码好,结果放在一个新byte[]返回。
getBytes 实际是做编码转换,你应该显式传入一个参数来指定编码,否则它会使用缺省编码来转换。
“字”在 GBK 编码下占 2 字节,在 UTF-16 编码下也占 2 字节,在 UTF-8 编码下占 3 字节,在 UTF-32 编码下占 4 字
“ new String(“字”).getBytes().length 返回的是3 ”,这说明缺省编码是 UTF-8. 如果你显式地传入一个参数,比如这样“ new String(“字”).getBytes(“GBK”).length ”,那么返回就是 2.
你可以在启动 JVM 时设置一个缺省编码,
假设你的类叫 Main,那么在命令行中用 java 执行这个类时可以通过 file.encoding 参数设置一个缺省编码。 比如这样:java -Dfile.encoding=GBK Main 这时,你再执行不带参数的 getBytes() 方法时,new String(“字”).getBytes().length 返回的就是 2 了,因为现在缺省编码变成 GBK 了。 当然,如果这时你显式地指定编码,new String(“字”).getBytes(“UTF-8”).length 返回的则依旧是 3.
否则,会使用所在操作系统环境下的缺省编码。
通常,Windows 系统下是 GBK,Linux 和 Mac 是 UTF-8. 但有一点要注意,在 Windows 下使用 IDE 来运行时,比如 Eclipse,如果你的工程的缺省编码是 UTF-8,在 IDE 中运行你的程序时,会加上上述的 -Dfile.encoding=UTF-8 参数,这时,即便你在 Windows 下,缺省编码也是 UTF-8,而不是 GBK。
总结:char在Java占两字节,大于两字节的不能存.在String里,每个字符大小不同。
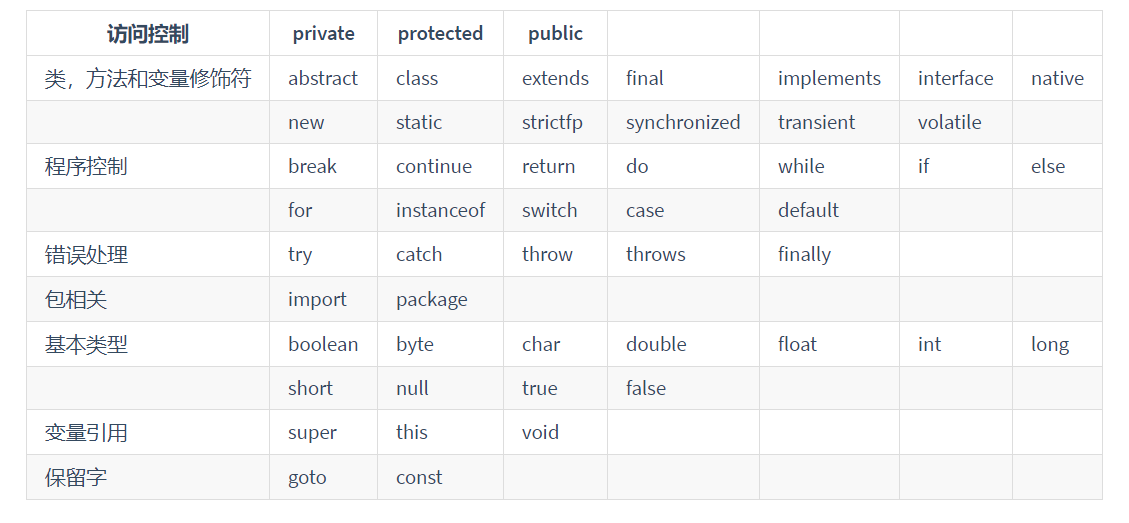
Java中有哪些常见的关键字?
Java泛型,以及类型擦除,常用的通配符
Java 泛型(generics)是 JDK 5 中引入的一个新特性, 泛型提供了编译时类型安全检测机制,该机制允许程序员在编译时检测到非法的类型。泛型的本质是参数化类型,也就是说所操作的数据类型被指定为一个参数。
Java泛型类型擦除以及类型擦除带来的问题

https://www.cnblogs.com/wuqinglong/p/9456193.html
大家都知道,Java的泛型是伪泛型,这是因为Java在编译期间,所有的泛型信息都会被擦掉,正确理解泛型概念的首要前提是理解类型擦除。Java的泛型基本上都是在编译器这个层次上实现的,在生成的字节码中是不包含泛型中的类型信息的,使用泛型的时候加上类型参数,在编译器编译的时候会去掉,这个过程成为类型擦除。
原始类型 就是擦除去了泛型信息,最后在字节码中的类型变量的真正类型,无论何时定义一个泛型,相应的原始类型都会被自动提供,类型变量擦除,并使用其限定类型(无限定的变量用Object)替换。
如在代码中定义List
在程序中定义了一个ArrayList泛型类型实例化为Integer对象,如果直接调用add()方法,那么只能存储整数数据,不过当我们利用反射调用add()方法的时候,却可以存储字符串,这说明了Integer泛型实例在编译之后被擦除掉了,只保留了原始类型。
在调用泛型方法时,可以指定泛型,也可以不指定泛型。
- 在不指定泛型的情况下,泛型变量的类型为该方法中的几种类型的同一父类的最小级,直到Object
- 在指定泛型的情况下,该方法的几种类型必须是该泛型的实例的类型或者其子类
1 | public class Test { |
其实在泛型类中,不指定泛型的时候,也差不多,只不过这个时候的泛型为Object,就比如ArrayList中,如果不指定泛型,那么这个ArrayList可以存储任意的对象。
1 | public static void main(String[] args) { |
类型擦除引起的问题及解决方法
3-1.先检查,再编译以及编译的对象和引用传递问题
Q: 既然说类型变量会在编译的时候擦除掉,那为什么我们往 ArrayList 创建的对象中添加整数会报错呢?不是说泛型变量String会在编译的时候变为Object类型吗?为什么不能存别的类型呢?既然类型擦除了,如何保证我们只能使用泛型变量限定的类型呢?
A: Java编译器是通过先检查代码中泛型的类型,然后在进行类型擦除,再进行编译。
那么,这个类型检查是针对谁的呢?我们先看看参数化类型和原始类型的兼容。
以 ArrayList举例子,以前的写法:
1 | ArrayList list = new ArrayList(); |
现在的写法:
1 | ArrayList<String> list = new ArrayList<String>(); |
如果是与以前的代码兼容,各种引用传值之间,必然会出现如下的情况:
1 | ArrayList<String> list1 = new ArrayList(); //第一种 情况 |
这样是没有错误的,不过会有个编译时警告。
不过在第一种情况,可以实现与完全使用泛型参数一样的效果,第二种则没有效果。
因为类型检查就是编译时完成的,new ArrayList()只是在内存中开辟了一个存储空间,可以存储任何类型对象,而真正设计类型检查的是它的引用,因为我们是使用它引用list1来调用它的方法,比如说调用add方法,所以list1引用能完成泛型类型的检查。而引用list2没有使用泛型,所以不行。
举例子:
1 | public class Test { |
通过上面的例子,我们可以明白,类型检查就是针对引用的,谁是一个引用,用这个引用调用泛型方法,就会对这个引用调用的方法进行类型检测,而无关它真正引用的对象。
泛型中参数话类型为什么不考虑继承关系?
在Java中,像下面形式的引用传递是不允许的:
1 | ArrayList<String> list1 = new ArrayList<Object>(); //编译错误 |
实际上,在第4行代码的时候,就会有编译错误。那么,我们先假设它编译没错。那么当我们使用list2引用用get()方法取值的时候,返回的都是String类型的对象(上面提到了,类型检测是根据引用来决定的),可是它里面实际上已经被我们存放了Object类型的对象,这样就会有ClassCastException了。所以为了避免这种极易出现的错误,Java不允许进行这样的引用传递。(这也是泛型出现的原因,就是为了解决类型转换的问题,我们不能违背它的初衷)。
再看第二种情况,将第二种情况拓展成下面的形式:
1 | ArrayList<String> list1 = new ArrayList<String>(); |
没错,这样的情况比第一种情况好的多,最起码,在我们用list2取值的时候不会出现ClassCastException,因为是从String转换为Object。可是,这样做有什么意义呢,泛型出现的原因,就是为了解决类型转换的问题。我们使用了泛型,到头来,还是要自己强转,违背了泛型设计的初衷。所以java不允许这么干。再说,你如果又用list2往里面add()新的对象,那么到时候取得时候,我怎么知道我取出来的到底是String类型的,还是Object类型的呢?
所以,要格外注意,泛型中的引用传递的问题。
3-2.自动类型转换
因为类型擦除的问题,所以所有的泛型类型变量最后都会被替换为原始类型。
既然都被替换为原始类型,那么为什么我们在获取的时候,不需要进行强制类型转换呢?
看下ArrayList.get()方法:
1 | public E get(int index) { |
可以看到,在return之前,会根据泛型变量进行强转。假设泛型类型变量为Date,虽然泛型信息会被擦除掉,但是会将(E) elementData[index],编译为(Date)elementData[index]。所以我们不用自己进行强转。当存取一个泛型域时也会自动插入强制类型转换。假设Pair类的value域是public的,那么表达式:
1 | Date date = pair.value; |
也会自动地在结果字节码中插入强制类型转换。
3-3.类型擦除与多态的冲突和解决方法
现在有这样一个泛型类:
1 | class Pair<T> { |
然后我们想要一个子类继承它。
1 | class DateInter extends Pair<Date> { |
在这个子类中,我们设定父类的泛型类型为Pair
1 | public Date getValue() { |
所以,我们在子类中重写这两个方法一点问题也没有,实际上,从他们的@Override标签中也可以看到,一点问题也没有,实际上是这样的吗?
分析:实际上,类型擦除后,父类的的泛型类型全部变为了原始类型Object,所以父类编译之后会变成下面的样子:
1 | class Pair { |
再看子类的两个重写的方法的类型:
1 |
|
先来分析setValue方法,父类的类型是Object,而子类的类型是Date,参数类型不一样,这如果是在普通的继承关系中,根本就不会是重写,而是重载。
我们在一个main方法测试一下:
1 | public static void main(String[] args) throws ClassNotFoundException { |
如果是重载,那么子类中两个setValue方法,一个是参数Object类型,一个是Date类型,可是我们发现,根本就没有这样的一个子类继承自父类的Object类型参数的方法。所以说,确实是重写了,而不是重载了。
为什么会这样呢?
原因是这样的,我们传入父类的泛型类型是Date,Pair
1 | class Pair { |
然后再子类中重写参数类型为Date的那两个方法,实现继承中的多态。
可是由于种种原因,虚拟机并不能将泛型类型变为Date,只能将类型擦除掉,变为原始类型Object。这样,我们的本意是进行重写,实现多态。可是类型擦除后,只能变为了重载。这样,类型擦除就和多态有了冲突。JVM知道你的本意吗?知道!!!可是它能直接实现吗,不能!!!如果真的不能的话,那我们怎么去重写我们想要的Date类型参数的方法啊。
于是JVM采用了一个特殊的方法,来完成这项功能,那就是桥方法。
首先,我们用javap -c className的方式反编译下DateInter子类的字节码,结果如下:
1 | class com.tao.test.DateInter extends com.tao.test.Pair<java.util.Date> { |
从编译的结果来看,我们本意重写setValue和getValue方法的子类,竟然有4个方法,其实不用惊奇,最后的两个方法,就是编译器自己生成的桥方法。可以看到桥方法的参数类型都是Object,也就是说,子类中真正覆盖父类两个方法的就是这两个我们看不到的桥方法。而打在我们自己定义的setvalue和getValue方法上面的@Oveerride只不过是假象。而桥方法的内部实现,就只是去调用我们自己重写的那两个方法。
所以,虚拟机巧妙的使用了桥方法,来解决了类型擦除和多态的冲突。
不过,要提到一点,这里面的setValue和getValue这两个桥方法的意义又有不同。
setValue方法是为了解决类型擦除与多态之间的冲突。
而getValue却有普遍的意义,怎么说呢,如果这是一个普通的继承关系:
那么父类的setValue方法如下:
1 | public ObjectgetValue() { |
而子类重写的方法是:
1 | public Date getValue() { |
其实这在普通的类继承中也是普遍存在的重写,这就是协变。
https://extremegtr.github.io/2016/07/11/Covariance-And-Contravariance-In-Java/
协变 / 共变(covariance)指的是子类型关系在类型变换的作用下保持原样。
不可变(invariance) 表示子类型关系在类型变换的作用下,既没有协变的效果,也没有逆变的效果。
逆变 / 反变(contravariance)指的是子类型关系在类型变换的作用下发生逆转。
双变(bivariance)表示子类型关系在类型变换的作用下同时拥有协变与逆变2种效果。
Java支持协变数组,你可能会问Java支持逆变数组吗?答案是:Java不支持逆变数组。
https://codingnote.com/2020/03/08/java-covariant-contravariant-invariant/
https://extremegtr.github.io/2016/05/30/JavaSE-study-advanced-generics/#u901A_u914D_u7B26_uFF08Wildcard_uFF09
Java下限通配符实现逆变
由于Java泛型的不可变性,generateIntegers() 生成的List不能放到输入参数output指定的List 中。那么有没有办法把 List 放到List 中呢?
答案是使用下限通配符来实现逆变。
正如大家所熟知的一个概念:在Java中,所有类型的父类型都是Object类型,方法的形参类型是Object,那这个方法就能接受任何类型的参数传递进来。这个推论正是实现该需求的关键所在。
根据上面的推导,我们可能会这么认为:既然Object是所有类型的父类型,那么List

并且,还有一点也许会有疑问,子类中的桥方法Object getValue()和Date getValue()是同 时存在的,可是如果是常规的两个方法,他们的方法签名是一样的,也就是说虚拟机根本不能分别这两个方法。如果是我们自己编写Java代码,这样的代码是无法通过编译器的检查的,但是虚拟机却是允许这样做的,因为虚拟机通过参数类型和返回类型来确定一个方法,所以编译器为了实现泛型的多态允许自己做这个看起来“不合法”的事情,然后交给虚拟器去区别。
总结:
在Java中,数组具有协变性,简单点来说就是子类型数组可以赋值给父类型数组进行使用,比如将Integer数组赋值给Object数组,这样来使用数组不会有警告甚至报错,但会存在运行时出错的风险,所以数组的协变性是具有瑕疵的,虽然它能这么用,但我们必须为此而承受一定风险。
Java泛型就不可以做出像数组这样的行为,因为泛型没有内建的协变类型,Java泛型具有不可变性(不具备协变性和逆变性)。但是,为了兼容遗留代码而被保留下来的原生类型确实可以做出这样的行为,但同时我们也非常清楚使用它就像使用数组的协变性一样意味着代码变得不再安全。
所以,制定Java标准的那群人想出了个法子使得泛型像数组一样具有这些特性,同时这种代替原生类型的方案必须是绝对安全的:他们通过给泛型增加通配符特性使得泛型在参数化后具有协变性或逆变性。
3-4.泛型类型变量不能是基本数据类型
不能用类型参数替换基本类型。就比如,没有ArrayList
3-5.编译时集合的instanceof
1 | ArrayList<String> arrayList = new ArrayList<String>(); |
因为类型擦除之后,ArrayList
那么,编译时进行类型查询的时候使用下面的方法是错误的
1 | if( arrayList instanceof ArrayList<String>) |
3-6.泛型在静态方法和静态类中的问题
泛型类中的静态方法和静态变量不可以使用泛型类所声明的泛型类型参数
举例说明:
1 | public class Test2<T> { |
因为泛型类中的泛型参数的实例化是在定义对象的时候指定的,而静态变量和静态方法不需要使用对象来调用。对象都没有创建,如何确定这个泛型参数是何种类型,所以当然是错误的。
但是要注意区分下面的一种情况:
1 | public class Test2<T> { |
因为这是一个泛型方法,在泛型方法中使用的T是自己在方法中定义的 T,而不是泛型类中的T。
==和equals的区别
== : 它的作用是判断两个对象的地址是不是相等。即判断两个对象是不是同一个对象。(基本数据类型==比较的是值,引用数据类型==比较的是内存地址)
equals() 方法存在两种使用情况:
情况 1:类没有覆盖 equals()方法。则通过equals()比较该类的两个对象时,等价于通过“==”比较这两个对象。使用的默认是 Object类equals()方法。
情况 2:类覆盖了 equals()方法。一般,我们都覆盖 equals()方法来两个对象的内容相等;若它们的内容相等,则返回 true(即,认为这两个对象相等)。
String 中的 equals 方法是被重写过的,因为 Object 的 equals 方法是比较的对象的内存地址,而 String 的 equals 方法比较的是对象的值。
当创建 String 类型的对象时,虚拟机会在常量池中查找有没有已经存在的值和要创建的值相同的对象,如果有就把它赋给当前引用。如果没有就在常量池中重新创建一个 String 对象。
hashCode()与 equals()
hashCode()介绍:
hashCode() 的作用是获取哈希码,也称为散列码;它实际上是返回一个 int 整数。这个哈希码的作用是确定该对象在哈希表中的索引位置。hashCode()定义在 JDK 的 Object 类中,这就意味着 Java 中的任何类都包含有 hashCode() 函数。另外需要注意的是: Object 的 hashcode 方法是本地方法,也就是用 c 语言或 c++ 实现的,该方法通常用来将对象的 内存地址 转换为整数之后返回。
散列表存储的是键值对(key-value),它的特点是:能根据“键”快速的检索出对应的“值”。这其中就利用到了散列码!(可以快速找到所需要的对象)
为什么要有 hashCode?
我们以“HashSet 如何检查重复”为例子来说明为什么要有 hashCode?
当你把对象加入 HashSet 时,HashSet 会先计算对象的 hashcode 值来判断对象加入的位置,同时也会与其他已经加入的对象的 hashcode 值作比较,如果没有相符的 hashcode,HashSet 会假设对象没有重复出现。但是如果发现有相同 hashcode 值的对象,这时会调用 equals()方法来检查 hashcode 相等的对象是否真的相同。如果两者相同,HashSet 就不会让其加入操作成功。如果不同的话,就会重新散列到其他位置。(Head fist java》第二版)。这样我们就大大减少了 equals 的次数,相应就大大提高了执行速度。
为什么重写 equals 时必须重写 hashCode 方法?
如果两个对象相等,则 hashcode 一定也是相同的。两个对象相等,对两个对象分别调用 equals 方法都返回 true。但是,两个对象有相同的 hashcode 值,它们也不一定是相等的 。因此,equals 方法被覆盖过,则 hashCode 方法也必须被覆盖。
hashCode()的默认行为是对堆上的对象产生独特值。如果没有重写 hashCode(),则该 class 的两个对象无论如何都不会相等(即使这两个对象指向相同的数据)
String类对hashcode的重写
1 |
|
在《Effective Java》第 42 页就有对 hashCode 为什么采用 31 做了说明:之所以使用 31, 是因为他是一个奇素数。如果乘数是偶数,并且乘法溢出的话,信息就会丢失,因为与2相乘等价于移位运算(低位补0)。使用素数的好处并不很明显,但是习惯上使用素数来计算散列结果。 31 有个很好的性能,即用移位和减法来代替乘法,可以得到更好的性能: 31 * i == (i << 5)- i, 现代的 VM 可以自动完成这种优化。这个公式可以很简单的推导出来。
31可以由31 * i == (i << 5) - i来表示,现在很多虚拟机里面都有做相关优化,使用31的原因可能是为了更好的分配hash地址,并且31只占用5bits!在java乘法中如果数字相乘过大会导致溢出的问题,从而导致数据的丢失,而31则是素数(质数)而且不是很长的数字,最终它被选择为相乘的系数的原因。
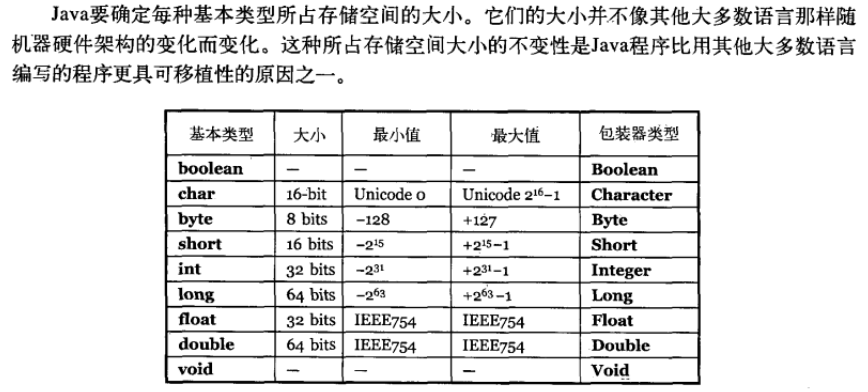
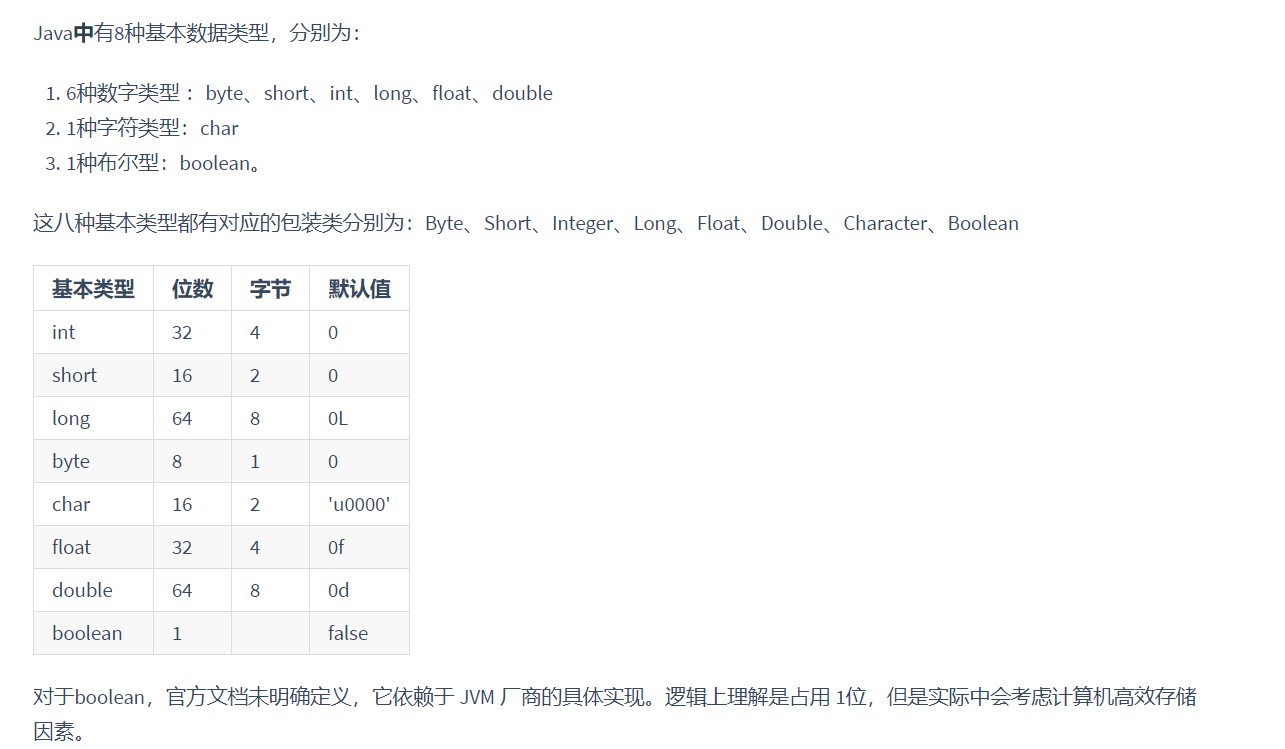
Java中的几种基本数据类型
注意:
- Java 里使用 long 类型的数据一定要在数值后面加上 L,否则将作为整型解析:
- char a = ‘h’char :单引号,String a = “hello” :双引号
Java 基本类型的包装类的大部分都实现了常量池技术,即 Byte,Short,Integer,Long,Character,Boolean;前面 4 种包装类默认创建了数值[-128,127] 的相应类型的缓存数据,Character创建了数值在[0,127]范围的缓存数据,Boolean 直接返回True Or False。如果超出对应范围仍然会去创建新的对象。
1 | public static Boolean valueOf(boolean b) { |
1 | private static class CharacterCache { |
1 | /** |
常量池是为了避免频繁的创建和销毁对象而影响系统性能,其实现了对象的共享。
例如字符串常量池,在编译阶段就把所有的字符串文字放到一个常量池中。
(1)节省内存空间:常量池中所有相同的字符串常量被合并,只占用一个空间。
(2)节省运行时间:比较字符串时,==比equals()快。对于两个引用变量,只用==判断引用是否相等,也就可以判断实际值是否相等。
为啥把缓存设置为[-128,127]区间?
1.技术规范。JLS7 5.1.7:If the value p being boxed is an integer literal of type int between -128 and 127 inclusive (§3.10.1), or the boolean literal true or false (§3.10.3), or a character literal between ‘\u0000’ and ‘\u007f’ inclusive (§3.10.4), then let a and b be the results of any two boxing conversions of p . It is always the case that a == b .
2.性能和资源之间的权衡(当然也可以调整缓存的正向最大值,自己看 IntegerCache 类的实现)。如果超出了范围,会从堆区new一个Integer对象来存放值。
1 | Integer a1 = new Integer(12); |
两种浮点数类型的包装类 Float,Double 并没有实现常量池技术。
1 | Integer i1 = 33; |
方法(函数)
Java 程序设计语言总是采用按值调用。也就是说,方法得到的是所有参数值的一个拷贝,也就是说,方法不能修改传递给它的任何参数变量的内容。
在 swap 方法中,a、b 的值进行交换,并不会影响到 num1、num2。因为,a、b 中的值,只是从 num1、num2 的复制过来的。也就是说,a、b 相当于 num1、num2 的副本,副本的内容无论怎么修改,都不会影响到原件本身。
而对象引用作为参数就不一样
1 | public static void main(String[] args) { |
结果:
1 | 1 |
array 被初始化 arr 的拷贝也就是一个对象的引用,也就是说 array 和 arr 指向的是同一个数组对象。 因此,外部对引用对象的改变会反映到所对应的对象上。
我们已经看到,实现一个改变对象参数状态的方法并不是一件难事。理由很简单,方法得到的是对象引用的拷贝,对象引用及其他的拷贝同时引用同一个对象。
很多程序设计语言(特别是,C++和 Pascal)提供了两种参数传递的方式:值调用和引用调用。有些程序员认为 Java 程序设计语言对对象采用的是引用调用,实际上,这种理解是不对的。由于这种误解具有一定的普遍性,所以下面给出一个反例来详细地阐述一下这个问题。
1 | public class Test { |
结果:
1 | x:小李 |
解析:
交换之前:
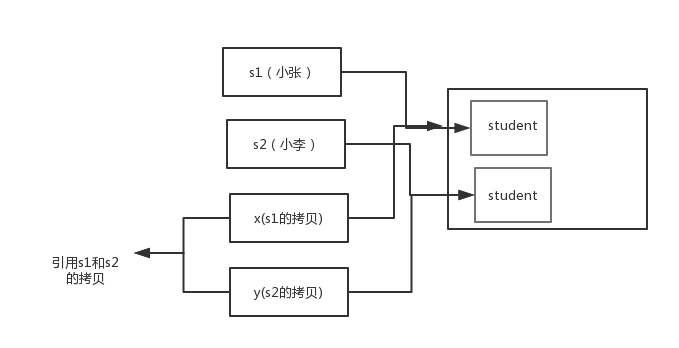
交换之后:
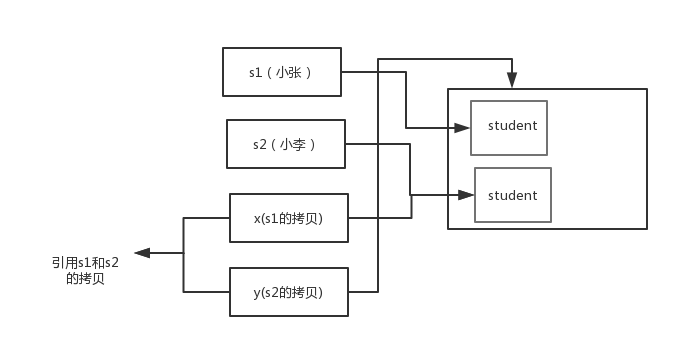
通过上面两张图可以很清晰的看出: 方法并没有改变存储在变量 s1 和 s2 中的对象引用。swap 方法的参数 x 和 y 被初始化为两个对象引用的拷贝,这个方法交换的是这两个拷贝
总结
Java 程序设计语言对对象采用的不是引用调用,实际上,对象引用是按 值传递的。
下面再总结一下 Java 中方法参数的使用情况:
- 一个方法不能修改一个基本数据类型的参数(即数值型或布尔型)。
- 一个方法可以改变一个对象参数的状态。
- 一个方法不能让对象参数引用一个新的对象。
参考:
《Java 核心技术卷 Ⅰ》基础知识第十版第四章 4.5 小节
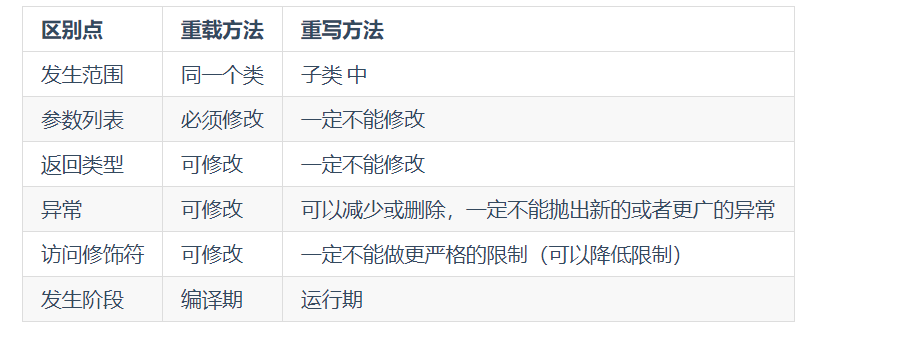
重载和重写
重载就是同样的一个方法能够根据输入数据的不同,做出不同的处理
重写就是当子类继承自父类的相同方法,输入数据一样,但要做出有别于父类的响应时,你就要覆盖父类方法
《Java 核心技术》中是这么说的
综上:重载就是同一个类中多个同名方法根据不同的传参来执行不同的逻辑处理。
重写发生在运行期,是子类对父类的允许访问的方法的实现过程进行重新编写。
- 返回值类型、方法名、参数列表必须相同,抛出的异常范围小于等于父类,访问修饰符范围大于等于父类。
- 如果父类方法访问修饰符为 private/final/static 则子类就不能重写该方法,但是被 static 修饰的方法能够被再次声明。
- 构造方法无法被重写
综上:重写就是子类对父类方法的重新改造,外部样子不能改变,内部逻辑可以改变
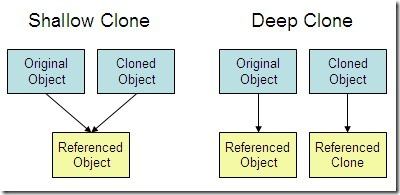
深拷贝 vs 浅拷贝
浅拷贝:对基本数据类型进行值传递,对引用数据类型进行引用传递般的拷贝,此为浅拷贝。
深拷贝:对基本数据类型进行值传递,对引用数据类型,创建一个新的对象,并复制其内容,此为深拷贝。